Bringing a new SaaS to life (part 2): Migrations in Spanner
In this post, I'll recount how I addressed an important aspect of developing and maintaining the database for the backend services, namely database migrations. For clarity, I'm talking about the changes you make to add/remove/change the SQL database schema as you develop new features or refactor the codebase. Unless you are clairvoyant, you won't be able to anticipate every need you have for a database before sitting down to write the code. And unless you intend to work alone forever, developers will need a way to share their schema changes with each other and production as new code is introduced to the codebase.
In this project, I had already decided that I would use Google Cloud Spanner for the database and implement services in Python, so I started on a quest to figure out how to perform database migrations. This is a foundational piece of any software development environment, so I thought there would be a well understood approach, but when I went searching for solutions, I had a hard time. Maybe the right answers are locked away in Google (I didn't work with Spanner when I was a Googler), or maybe they are so well known that no one bothers to write up the issues. But what I suspect is that few hobbyists are using this environment, so there isn't a lot of blogging and open source activity in this area.
Database Migrations at Square
When I worked at Square, we built the cloud infrastructure ourselves. Public cloud offerings were still pretty new. We used open source libraries along with our own logic based on experience working on private cloud infrastructure at other companies. Each microservice that my teams owned also owned their own datastores. We used Redis for some systems, but for the most part we used MySQL databases and had a team of very capable engineers who built tooling for running MySQL effectively. There were tools and observability in place to make sure the tooling replicated databases effectively across regions for keeping warm standbys ready. We monitored storage use and other metrics around the database. The coolest thing that they made for us was a database migration service. We would write the SQL commands for updating the database schema and write them into separate files we checked into the repo. Then, we could run these migrations in different environments before upgrading the code.
OK, so maybe using a SQL file to update the schema doesn't seem like rocket science, but there was one piece of this service that was non-trivial, which was adding a way to migrate database indexes when you wanted to change them. It would run and create a new table with the new index (which could take many hours or even days on a large table) and keep it up to date as new data arrived. Then, when you were ready, it would swap the new table for the old one. Along the way, you also got a nicely compacted table and were able to reclaim free space.
The other major piece of tooling we used was a way to run an executable to perform a backfill. If we changed the schema to add new fields and we didn't want to use 'NULL' as a default, we could populate the new fields with an algorithm that scanned and converted the entire database. Again, backfilling could take hours or days, just like rebuilding an index.
I knew that if I wanted to build a production backend service that I'd need to address migrations and backfills somehow. I didn't want to re-invent the wheel so I went looking for open source and commercially available solutions. Finding anything comparable for Spanner, however, proved harder than expected.
Searching for Open and Commercial Database Migration Tools
I started using Google Search and various AI tools to look for how to address the database migration issue.
Running a quick search I found the "Spanner Migration Tool", which sounds like it would be the right thing,
but what I quickly ran into was that the word "database migration" means different things in different
contexts. For most searches, you'll find tools that will help you import data from one type of datastore
to another, and that seems to be the real purpose of the Spanner Migration Tool. It will help you migrate
your database schema from MySQL or Postgres into the Spanner DDL format. That is very cool, but not
the problem I'm trying to solve.
Delving deeper into the Google Documentation for Spanner, you'll see it talking about schema updates and all the details you need to know about how to do this by running DDL commands or even programmatically making changes with gRPC calls. But strangely missing is any kind of description of tooling around these updates. Surely, not everyone runs these commands by hand every time they want to make a change. I went looking further.
Since I am using Python and SQLAlchemy in my codebase, using the Alembic library came up quickly. Alembic is a very capable tool which solves the migration problem well for many databases. You write a Python script that uses an Alembic API to create and alter tables, columns, and indexes. It can even auto-generate migrations for you! I started looking into it and found that it works by understanding the schema from your ORM models in code. It then generates whatever commands your database needs using the programmatic API. That is super cool, and if you are all-in on SQLAlchemy and the ORM model, then it seems like a great way to go. But I started encountering friction when actually trying to implement this. Now that I have more experience and have read through some of the documentation in sqlalchemy-spanner I might have been able to get this working with native Alembic. But my initial tries didn't go so well and I was frustrated that I would have to work from the SQL statements that I knew to write, turn them into the Alembic/SQLAlchemy API calls, and then verify that they actually created the schema I wanted. I started looking elsewhere.
The next tool I came across was yoyo. These worked more the way I was used to. You write SQL, and yoyo will run it for you at the appropriate times. I gave this a shot, but since it doesn't natively support Spanner, it looks like I'd have to write that myself. It seemed like a dead end.
The next tools I looked at seriously were commercial tools. Atlas sounds like a great product, but as I'm just starting out, I didn't really want to embed something that looks like it's aimed at (and priced for) enterprise scale deployment.
Postgres Adapter for Spanner
Early on I did discover the Postgres adapter for Spanner, and thought about how I could use it.
The adapter is a standalone Go service that proxies the Postgres protocol and turns
it into Spanner gRPC calls.
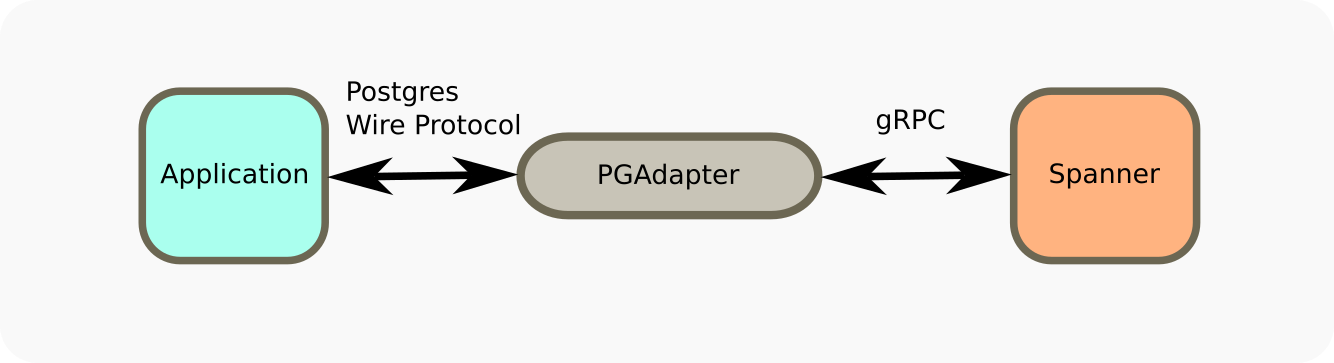
I can see how this solves problems for a lot of people. It allows you to migrate from Postgres to Spanner if you already have a sizable investment in Postgres. Furthermore, it addressed a crucial concern I had with the native Spanner driver for Python, which was that it did not support async style calls (apparently Google remedied this in the six months since I started the project). I could use the async Postgres driver for better compatibility with FastAPI.
I think using the Postgres adapter would have opened up more conventional ways of solving the
database migration problem. For example, yoyo might have been a good alternative. I also
might not have hit friction trying to do Spanner specific things because I would be aiming for Postgres compatibility.
There are a lot of reasons why I didn't want to go this route. Yes, a service written in Go can have low latency, but in the end, it does add latency compared to using a native driver. My architecture was to put services in many datacenters to be close to the callers and minimize round trip time (we had a 50ms latency goal). I didn't feel it was wise to build in an extra 5-10ms to every round trip just for adding this flexibility. Also impeding me was my own stinginess. Although I am just trying to make an MVP, I was concerned about adding cost and complexity too early. I didn't want to configure a dedicated service in every environment to just proxy database calls. I already had 4 microservices configured and had good reasons for each one. This seemed like not a great reason to add a new service.
In summary:
- It added latency
- It added complexity to the deployment
- It got in the way of taking advantage of Spanner native optimizations
Later I reconsidered using the Postgres adapter in a different context. One downside of choosing Spanner for your
project is that, other than an in-memory emulator, Google forces you to provision a Spanner database in the cloud
to use it. I had what I thought was a clever idea: I could use Postgres for development and sandbox environments to save on
costs and allow developers to run a local copy of the database.
Then, I could use the Postgres dialect and Postgres Spanner adapter to run in staging and production.
The only plausible ways I came up with to implement this scheme was to either use the postgres adapter, or to keep the database schema source of truth in Postgres dialect and use a tool like the Spanner Migration Tool to translate the schema into Spanner pretty much any time I wanted to move things to the Spanner database. It is pretty clear that the tools don't want to be used this way and I would bump up against the same issues I had identified before so I didn't spend too much time on it. If someone has found clever ways to do this, I'd love to hear more!
My Experience with Flyway
Flyway is commercial software for managing database migrations that supports many different databases, including Google Spanner. They have a community edition and the simple SQL file based up/down migration scripts I was familiar with. As a standalone tool, it was language agnostic. Thus, it felt like a good fit for my project.
Flyway has binaries you can download for Mac or Linux. I installed it natively at first, but then I started playing around with Docker and used their published flyway/flyway Docker container. Since Flyway is a Java app, you also need a JVM installed to run it. This turns out to be a path of least resistance for keeping the Flyway image up to date and being able to easily run in CI or a new environment.
Flyway did the migration job just fine for me. I noticed that it has safeguards in it to keep you from doing things like updating an old migration file. That is a good best practice. When I had no live systems, I often did revisionist things like put small changes back in the original table creation call, and sometimes Flyway complained.
Rolling my own Alembic-like migration tool
Time went by. At some point, I spent a lot of time trying to make my CI runs more performant.
Fortunately, I had a lot of success and got my times down from around the 8 minute mark to around 3 minutes,
mainly by switching to a self-hosted GitHub runner.
It was about then that I realized that the time to manage the re-installing or downloading the Flyway container (20-30 seconds) had become a dominant
part of my CI time when running GitHub Actions. The switch to a self-hosted runner mitigated the issue by
installing the tool once and keeping the environment active between CI runs. Later, the issue re-emerged
when setting up devcontainer workflows and trying to manage the database from the Google Cloud Shell.
The Docker image was pretty big, which made sense as it had to host a JVM and support for many different
databases. But surely we don't need over 400MB of logic just to run a few SQL scripts!
For what it was doing for me, it sure seemed like overkill.
After some discourse with an AI chatbot, I went back to exploring the open-source Alembic library. It suggested that the best way to integrate Alembic was to embed the Spanner DDL right into the script, bypassing the Alembic API. I let AI take a shot and it did some horrible hacking, grabbing the Spanner driver instance out from under SQLAlchemy using 'hasattr()', because you can't really hide anything from Python. I discovered that Spanner's calls to change the schema couldn't re-use the same functions that you might use to run a transaction. I also discovered that although the function call returned, you couldn't run another DDL command until the first one finished.
Here's an abbreviated version of the 'wait until finished' part that gave me the most headaches:
for attempt in range(max_retries):
try:
operation = self.database.update_ddl(statements)
operation.result()
return
except Exception as exc:
message = str(exc)
if (
"Schema change operation rejected" in message
or "concurrent schema change" in message
):
if attempt == max_retries - 1:
raise DatabaseError(f"Retries exceeded {max_retries}") from exc
# Print helpful diagnostics after 10 attempts
if attempt == 10:
max_seconds = max_retries * delay_seconds
print(
f"{attempt} attempts so far, still retrying for up to {max_seconds} more seconds."
)
time.sleep(delay_seconds)
continue
raise DatabaseError(f"DDL execution failed: {exc}") from exc
What happens here is that the first SQL statement returns success, but is actually still running in the background. The second statement will fail with an error. The timing of this was sensitive and presented itself as intermittent failures and hangs. I finally landed on this strategy to just keep retrying the next statement until successful. After overcoming this issue, I was able to get my hacked Alembic migrations to work pretty much just like Flyway. That is, a tool that read a SQL up/down migration script from a file and ran it. Tweaking the delays and number of retries made it run faster than Flyway, too.
After using this AI generated Frankenstein Alembic, I carefully dissected the code and realized that very little Alembic code was being used at all. With a little bit more prompting, I was able to completely eliminate the Alembic library and the ugly grab of the Spanner driver instance. I instructed the tool to take the same arguments as Alembic, so it should be easy to convert back later if desired. It's less than 800 lines of Python code, excluding comments and tests.
Conclusions
While I didn't intend to write my own database migration tool, that's what I ended up doing. I wouldn't have recommended it, but having tried to use several alternatives, it just turned out to be the best solution for this problem. My bespoke migration tool runs faster than the commercial tools I tried, is more transparent than trying to figure out what the Alembic native solution is doing, and is so lightweight, it's easy for me to debug or extend if need be.
For backfills, I've only had a need to run one since starting the project, which was to normalize values in an existing field. A one-off command-line tool was sufficient. I haven't tried to generalize it further.
That's not to say that this solution would be for everyone. I would say that if I didn't care about what the schema actually looked like and never wanted to touch SQL, the auto-migration capabilities of Alembic are attractive. As it turns out, I'm now writing code with multiple languages (Go and Python) and finding that the ORM abstractions can get in the way. Also, if I had a large development team and some kind of crazy number of tables, the extra features of Flyway or Atlas might be appealing.
In the next part of "Bringing a new SaaS to life", I will switch directions and drill down into the use of the Bazel build tool in the project.